专属算力
什么是专属算力
专属算力是平台为保障关键工作流稳定、高效运行而提供的独立资源服务,通过将重要工作流添加到专属算力中,避免平台其他流程堵塞的影响。
专属算力不是提高了工作流本身的执行速度,而是保证专属算力中的工作流能够稳定执行,不会受到其他工作流的影响。
专属算力的核心优势在于:
- 独立资源: 为每个专属算力分配独立的计算资源,确保工作流独享资源,不受其他工作流影响。
- 稳定执行: 专属算力中的工作流拥有独立的 Kafka Topic 队列,避免与公共队列中的消息竞争,从而保证工作流能够稳定、高效地执行。
- 隔离保护: 通过将关键工作流与普通工作流隔离,有效降低受普通工作流堵塞的影响。
工作原理简述:
- 触发执行: 当专属算力中的工作流被触发时,会进入其独立的 Kafka Topic 队列。
- 独立消费: 专属的消费服务会实时消费该 Topic 中的消息,并按照预设的逻辑执行工作流。
- 资源保障: 专属算力所使用的计算资源和存储空间,均为独享资源,不会被其他工作流占用。
适用场景:
- 高优先级工作流: 需要快速响应、及时处理的工作流。
- 复杂工作流: 配置复杂、计�算量大并且需要大批量触发的工作流。(放入独立的高配规格专属资源示例中,避免这种复杂工作流在公共队列造成普通工作流排队)
部署架构
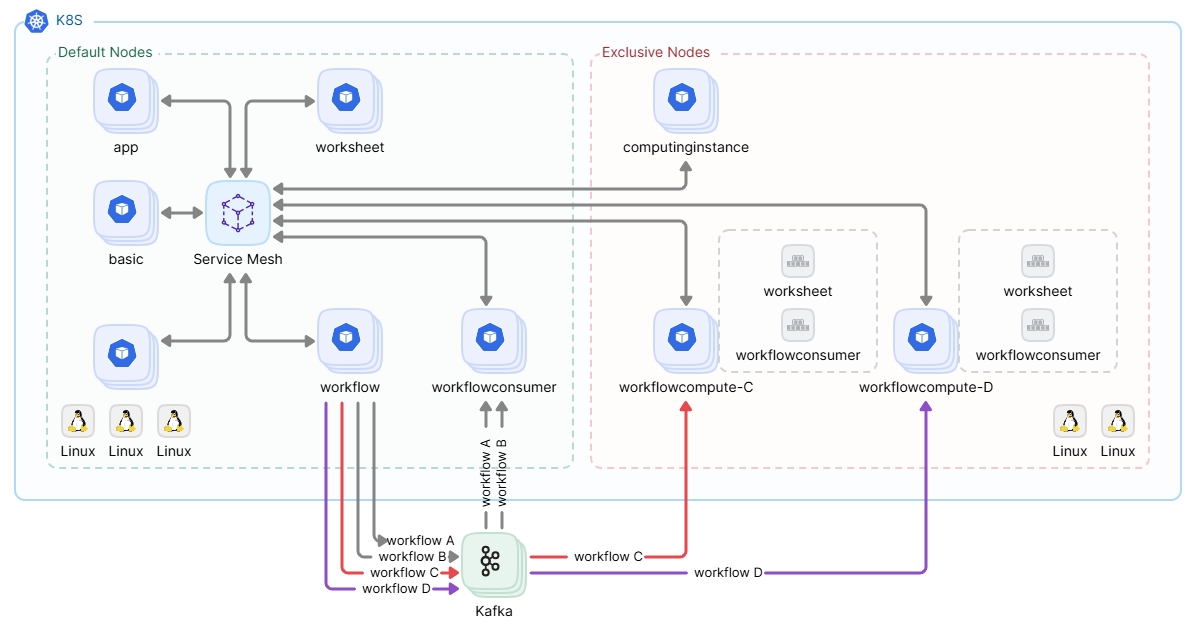
如上图,在现有 Kubernetes 集群增加2个新节点作为专属算力服务的专属资源,这里创建了2个专属算力 workflowcompute-C 和 workflowcompute-D。通过将 workflow C 配置为使用专属算力 workflowcompute-C 消费后,workflow C 的执行都将使用 workflowcompute-C 分配的资源。workflow D 同理。
使用专属算力
专属算力服务需要独立密钥授权,并且仅支持在集群模式下部署使用。
完成部署与添加授权后,可以在此页面,选择实例规格进行创建。
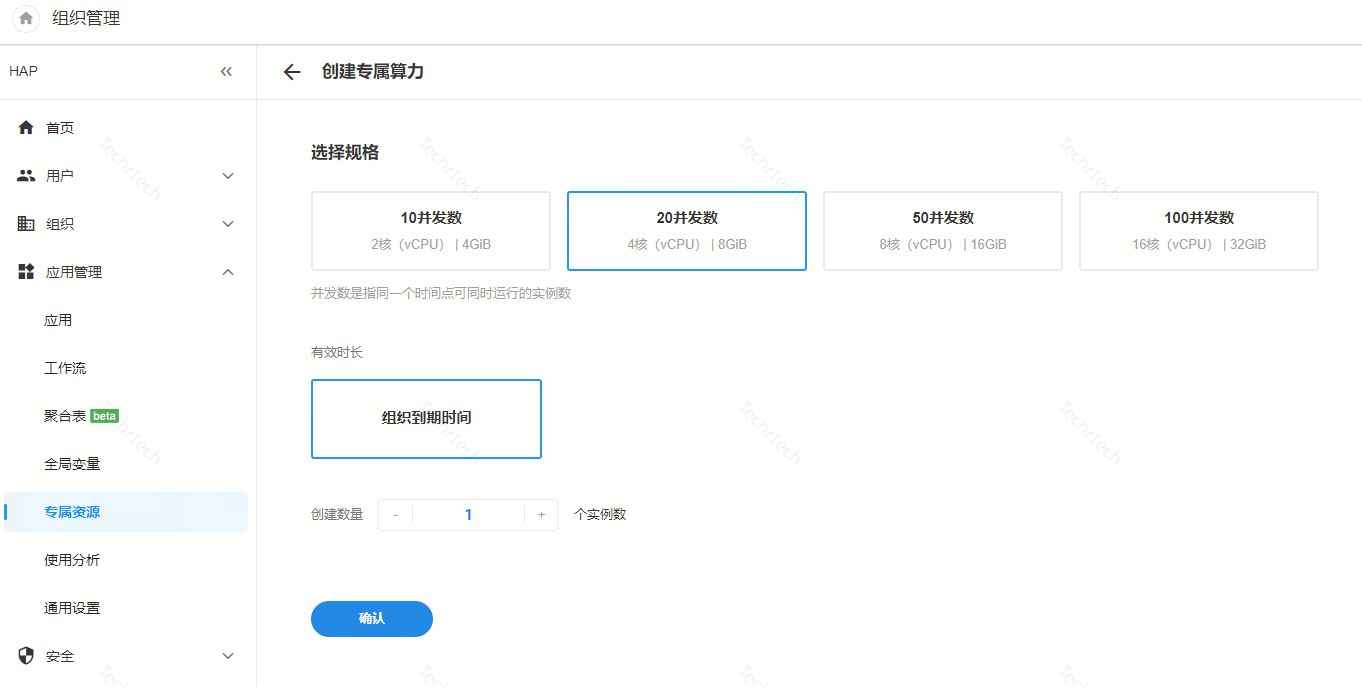
专属算力实例规格中的并发概念:
- 20并发:代表独立的 Kafka Topic 有 20 个分区,独立的工作流消费服务有20个线程,独立的工作流与工作表服务最大可占用4核8GB资源。
- 100并发:代表独立的 Kafka Topic 有 100 个分区,独立的工作流消费服务有100个线程,独立的工作�流与工作表服务最大可占用16核32GB资源。
- 理论上 Kafka Topic 分区越大,工作流消费服务线程越大,并行可处理的工作流也越多。
部署服务器规格怎么选?
专属算力服务利用 Kubernetes 污点特性,将专属算力服务独立运行在与微服务隔离的服务器中,从而避免受到其他服务资源占用的影响,所以部署专属算力服务需要新增独立服务器。
先规划所需专属算力实例数量及规格大小,再规划部署服务器配置与数量。
例如:需要创建2个20并发与2个50并发的专属算力实例,那么最低需要2台16核32GB的服务器,每台服务器磁盘大小固定200G即可。